(LSJ) The Core Model for Secure Enterprise AI: Public Training, Private Reasoning
/(LSJ) The Core Model for Secure Enterprise AI: Public Training, Private Reasoning
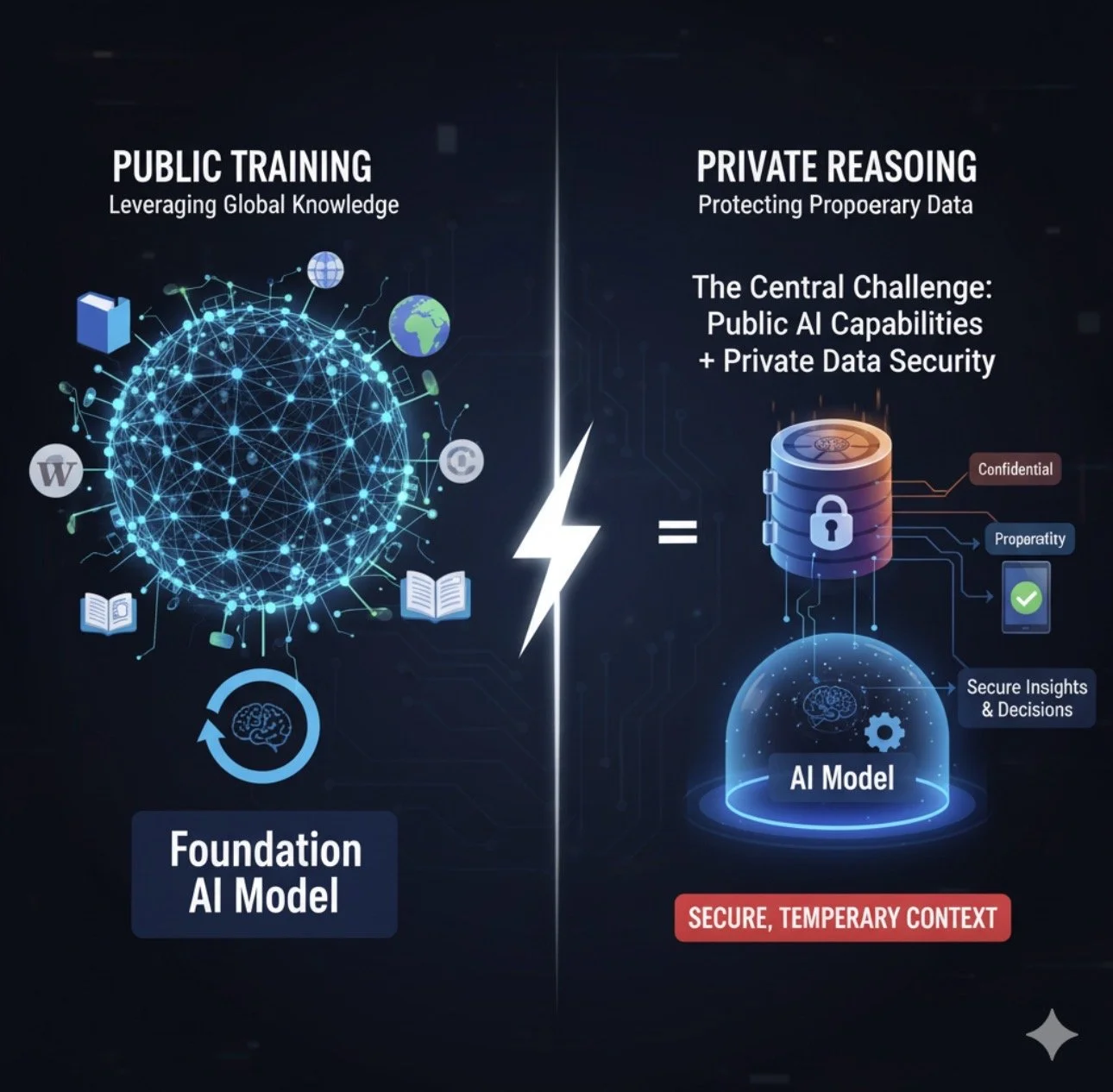
The central challenge in deploying powerful AI within a business is leveraging its vast capabilities without exposing sensitive, proprietary information. The solution is a secure, two-step model that forms the bedrock of modern Enterprise AI: training the model on public data, but having it reason with your private data in a secure, temporary context.
Phase 1: Building the Engine 🎓 — Training on Public Data
This is the foundational stage where a general-purpose AI model, like Google's Gemini, is created.
What is the data? The model is trained on a massive, diverse dataset from the public internet, including Wikipedia, publicly available books, scientific articles, and open-source code.
* What does it learn? The objective is not to memorize facts but to learn the fundamental patterns, logic, and structure of language and reasoning. It learns grammar, coding principles, common sense, and how to form a coherent argument.
Think of this as a brilliant new hire graduating from the world's best university. They possess incredible general knowledge and analytical skills but know nothing specific about your company. The result is a powerful, but generic, "reasoning engine" ready for any task.
Phase 2: Applying the Engine 🔒 — Reasoning with Private Data
This is where the generic engine becomes your company's unique competitive advantage.
What is the data? This is your proprietary and private data: internal financial reports, customer data from your CRM, project plans, and confidential source code.
How does it work? When an employee asks a question, the system uses a technique like Retrieval-Augmented Generation (RAG). It retrieves relevant snippets of your private data and provides them to the AI model as temporary context for that specific query only. The model then uses its general reasoning ability to analyze the private information you just gave it and generate an answer.
Continuing the analogy, you hand your brilliant new hire a confidential project report and ask for a summary. They use their general skills to analyze your document for that single task. Crucially, your private data is never used to retrain or permanently modify the foundational model. Once the task is complete, that specific context is discarded.
Why This Separation is the Enterprise Standard
This two-step model is not just a technical choice; it's a strategic necessity.
Security and Privacy: This is paramount. Your sensitive data is never absorbed into the core model, eliminating the risk of it being leaked or exposed to other users or companies.
Competitive Advantage: Your private data is your unique asset. This model allows you to apply state-of-the-art AI to your "secret sauce," generating insights that are specific to your business and impossible for competitors to replicate.
Cost and Efficiency: Training a foundational model from scratch is prohibitively expensive. This approach allows you to leverage that massive initial investment and apply it to your specific needs in a highly efficient and targeted manner.