
Lifetime World Model on DWS IQ -ratkaisujen perusta.
Käyttöönota pilvessä tai private cloudissa
Lifetime World Model on DWS IQ -ratkaisun ydin. Se yhdistää maailman rakenteen (agentit, objektit, resurssit) ja objektien elinkaaren hallinnan. Ratkaisu voidaan ottaa käyttöön joustavasti joko pilvestä tai yrityskohtaisena private cloud -versiona. Näin varmistetaan, että toimialasi saa oikean deployment-mallin – kustannustehokkuuden, skaalautuvuuden ja GDPR-yhteensopivuuden huomioiden.
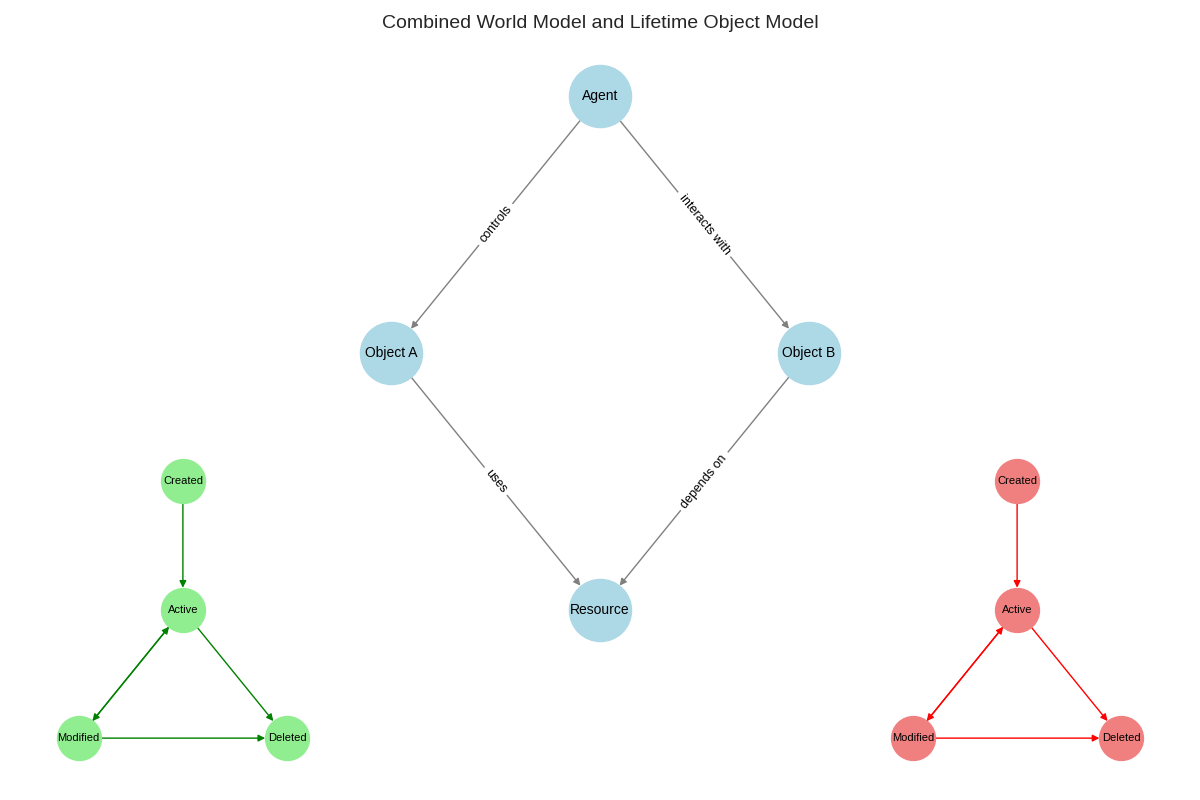
Lifetime world model and object model (UML State diagram).
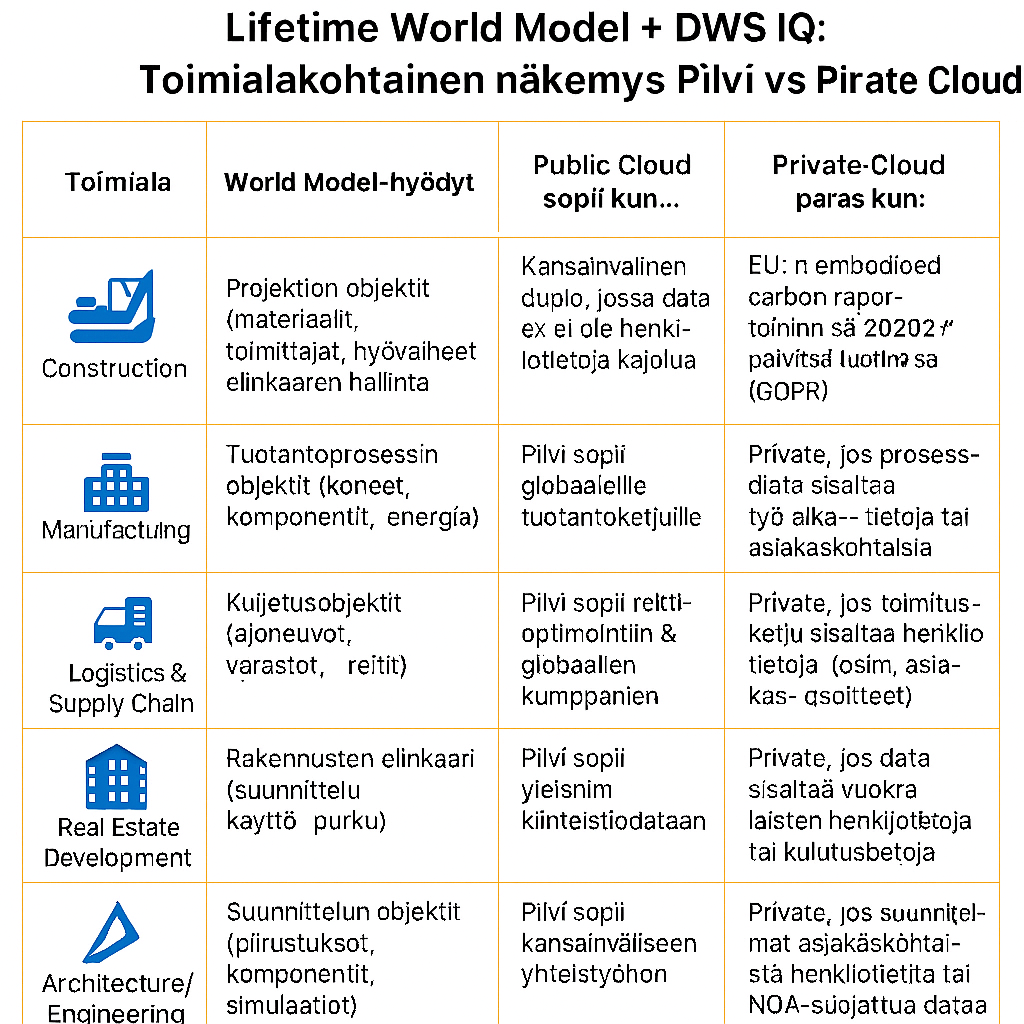
📊 Toimialakohtainen näkymä
ToimialaWorld Model -hyödyt
🏗️ Rakentaminen (Construction)
World Model -hyödyt: Projektien objektit – kuten materiaalit, toimittajat ja työvaiheet – mallinnetaan koko elinkaaren ajan. Tämä mahdollistaa tarkemman päästöseurannan ja projektinhallinnan.
Public Cloud sopii kun: Projektit ovat kansainvälisiä eikä data sisällä henkilötietoja.
Private Cloud paras kun: EU:n embodied carbon -raportointi vaatii datan säilyttämistä EU-alueella (GDPR:n mukaisesti).
🏭 Valmistava teollisuus (Manufacturing)
World Model -hyödyt: Tuotantoprosessin objektit – koneet, komponentit ja energiavirrat – hallitaan elinkaarimallilla, mikä tukee energiatehokkuutta ja prosessien optimointia.
Public Cloud sopii kun: Kyseessä on globaali tuotantoketju, jossa data ei ole arkaluontoista.
Private Cloud paras kun: Prosessidata sisältää henkilöstön työaikatietoja tai asiakaskohtaisia sopimuksia.
🚚 Logistiikka ja toimitusketjut (Logistics & Supply Chain)
World Model -hyödyt: Kuljetusobjektit – ajoneuvot, varastot ja reitit – optimoidaan elinkaaren mukaan, mikä parantaa tehokkuutta ja vähentää päästöjä.
Public Cloud sopii kun: Reittioptimointi tapahtuu globaalien kumppaneiden kanssa ilman henkilötietoja.
Private Cloud paras kun: Toimitusketju sisältää henkilötietoja, kuten asiakasosoitteita.
⚡ Energia ja infrastruktuuri (Energy & Utilities)
World Model -hyödyt: Energian tuotanto- ja jakeluobjektit – kuten tuuli-, aurinko- ja vetyjärjestelmät – mallinnetaan elinkaaren kautta, mikä tukee Fit for 55 -tavoitteita.
Public Cloud sopii kun: Kyseessä on yleinen energiavirtojen optimointi.
Private Cloud paras kun: Data liittyy kriittiseen infrastruktuuriin tai kansalliseen turvallisuuteen (GDPR).
🏢 Kiinteistökehitys (Real Estate Development)
World Model -hyödyt: Rakennusten elinkaari – suunnittelu, käyttö ja purku – hallitaan World Modelin avulla, mikä tukee hiilineutraalia kiinteistökehitystä.
Public Cloud sopii kun: Kyseessä on yleinen kiinteistödatan hallinta.
Private Cloud paras kun: Data sisältää vuokralaisten henkilötietoja tai kulutustietoja.
📐 Arkkitehtuuri ja suunnittelu (Architecture & Engineering)
World Model -hyödyt: Suunnitteluobjektit – piirustukset, komponentit ja simulaatiot – versioidaan ja optimoidaan elinkaaren kautta.
Public Cloud sopii kun: Kansainvälinen yhteistyö ja pilvipohjainen suunnittelu.
Private Cloud paras kun: Suunnitelmat sisältävät asiakastietoja tai NDA-suojattua dataa.
🗑️ Jätehuolto (Waste Management)
World Model -hyödyt: Jäteobjektien elinkaari – syntypaikka, lajittelu, kierrätys ja loppusijoitus – mallinnetaan, mikä tukee kiertotaloutta.
Public Cloud sopii kun: Kyseessä on yleinen jätevirtojen optimointi.
Private Cloud paras kun: Data sisältää kotitalousasiakkaiden henkilötietoja.
🔑 Yhteinen hyöty
Yksi malli, kahdeksan teollisuutta – sama World Model tukee eri toimialoja.
Deployment joustavasti – pilvi nopeaan skaalaukseen, private cloud GDPR- ja compliance-vaatimuksiin.
Agentit käytännön työssä – reaaliaikaiset agentit valvovat, optimoivat ja raportoivat toimialakohtaisesti.
📣 Call-to-Action
“Varaa DWS IQ -auditointi ja näe, mikä käyttöönottotapa sopii parhaiten toimialallesi.”
Agenttitehdas - Tulokset:
35% tuotantoajan väheneminen
50% virheellisten kappaleiden väheneminen
28% laadunvalvonnan nopeuden parannus
60% dokumentointityön väheneminen
Yhteystiedot: Ota yhteyttä Lifetime Consultingiin selvittääksesi, miten agenttitehdas voi muuttaa organisaatiosi toimintatapoja: Lataa Agenttitehdas oppaamme (ilmainen) tästä:
Verkkosivut: lifetime.fi
Sähköposti: info@lifetime.fi
Erikoispalvelut: Azure AI, Google AI, Digital Workspace (DWS) -ratkaisut
Lifetime Consulting: Strateginen kumppani AI-matkallasi
Lifetime Consulting toimii strategisena kumppanina yrityksille, ohjaten niitä koko AI-matkan läpi – aina alkuvaiheen strategiasta ja konsultoinnista agenttitehtaan toteutukseen, räätälöityyn kehitykseen ja kestävään operatiiviseen hallintaan pilviympäristössä.
Strategisen kumppanuuden edut
1. Kokonaisvastuu
Yksi kumppani koko AI-matkan ajan
Selkeä vastuunjako ja yhteyshenkilöt
End-to-end -ratkaisu strategiasta operointiin
2. Teknologiariippumattomuus
Parhaat työkalut kulloiseenkin tarpeeseen
Microsoft, Google ja AWS -sertifikaatit
Vendor lock-in -riskin minimointi
3. Pohjoismainen asiantuntemus
Suomalainen toimintatapa ja kulttuuri
Ymmärrys pohjoismaisista säädöksistä ja standardeista
Paikalliset referenssit ja case-esimerkit
4. Ketterä ja iteratiivinen lähestymistapa
Nopeat pilotit ja prototyypit
Asteittainen käyttöönotto ja skaalaus
Jatkuva palautteen kerääminen ja optimointi
5. Tiedonsiirto ja itsenäisyys
Kattava dokumentaatio
Tiimien koulutus ja osaamisen kehittäminen
Mahdollisuus siirtyä itsenäiseen ylläpitoon
Palvelumallit
Platinum Partnership
Kokonaisvaltainen strateginen kumppanuus
Dedikoidut asiantuntijat ja projektipäällikkö
Jatkuva konsultointi ja strateginen ohjaus
Agenttitehtaan full-service operaatio
24/7 tekninen tuki ja SLA-takuut
Neljännesvuosittaiset liiketoiminta-arvioinnit
Gold Engagement
Projektikohtainen toteutuskumppanuus
Agenttitehtaan toteutus avaimet käteen -periaatteella
Räätälöidyt agentit määriteltyihin käyttötapauksiin
Pilviympäristön pystytys ja konfigurointi
Tiimin koulutus ja tiedonsiirto
3 kuukauden tukijakso käyttöönoton jälkeen
Silver Consulting
Konsultatiivinen tukipalvelu
Strateginen suunnittelu ja teknologiavalinta
Arkkitehtuurisuunnittelu ja best practices
Koodikatselmoinnit ja tekninen mentorointiI
Ad hoc -konsultaatio tuntipohjaisesti
Tiimien koulutustyöpajat
Bronze Advisory
Asiantuntija-arvioinnit ja auditoinnit
Olemassa olevien agenttijärjestelmien auditointi
Optimointisuositukset ja roadmap
Kertaluonteiset työpajat ja koulutukset
Teknologiaselvitykset ja POC-arvioinnit
Yhteystiedot
Aloita AI-matkasi Lifetime Consultingin kanssa
Verkkosivut: lifetime.fi
Sähköposti: info@lifetime.fi
Erikoisosaamisalueemme:
Azure AI -konsultointi ja -toteutukset
Google AI -projektit ja Vertex AI
Digital Workspace (DWS) -ratkaisu Google Cloud/Vertex AI -pohjaisesti
Moniagenttijärjestelmät ja Agent Foundry -toteutukset
Vahvistusoppiminen (RL) ja jatkuva agenttioptimointi
Sertifikaatiot:
Microsoft ISV Partner
AWS Partner
Google Cloud Partner
AI Provider Partnerships
Lifetime Consulting – Suomalainen IT-konsulttiyritys, joka erikoistuu pilviratkaisuihin, AI/ML-toteutuksiin ja yrityksen digitaaliseen transformaatioon. Yli 15 vuoden kokemus varmistaa luotettavan ja asiantuntevan kumppanuuden.
0924 4K with Sound. Artist: Dyella Song; Back to 80s.
Oppivat agenttikehykset : Whitepaper (FREE) + työpaja + Agent Factory perustaminen
Oppivat agenttikehykset : Whitepaper (FREE) + työpaja + Agent Factory perustaminen
Lifetime Consulting tarjoaa räätälöityjä asiantuntijapalveluita edistyneiden agenttijärjestelmien ja agenttitehtaiden hankesuunnittelussa, agenttitehtaiden kehityksessä ja agenttien käyttöönotossa.
Agenttitehdas -ratkaisulla saavutatte nämä (best case) tulokset:
35% tuotantoajan väheneminen
50% virheellisten kappaleiden väheneminen
28% laadunvalvonnan nopeuden parannus
60% dokumentointityön väheneminen
Yhteystiedot: Ota yhteyttä Lifetime Consultingiin selvittääksesi, miten agenttitehdas voi muuttaa organisaatiosi toimintatapoja:
Verkkosivut: lifetime.fi
Sähköposti: info@lifetime.fi
Erikoispalvelut: Azure AI, Google AI, IBM AI, AWS AI, Lifetime Digital Workspace (Private AI) -ratkaisut.
Lataa Oppivat agenttikehykset Opas (FREE)
Oppivat agenttikehykset: Kattava katsaus
Johdanto
Tekoälyagentit edustavat merkittävää edistysaskelta kohti yleistä tekoälyä (AGI), mahdollistaen järjestelmiä, jotka eivät ainoastaan suorita ennalta määriteltyjä tehtäviä vaan oppivat, mukautuvat ja parantavat suorituskykyään ajan myötä. Perinteiset LLM-pohjaiset (Large Language Model) agentit nojautuvat staattisiin, esiharjoitettuihin malleihin, jotka kärsivät merkittävistä rajoituksista: ne eivät sopeudu dynaamisiin ympäristöihin, eivät opi virheistään eivätkä parane käyttökokemuksen myötä.
Oppivat agenttikehykset ratkaisevat nämä haasteet integroimalla vahvistusoppimisen (Reinforcement Learning, RL) ja muita oppimismekanismeja agenttien kehitysprosessiin. Tämän dokumentin tarkoituksena on tarjota kattava katsaus keskeisimpiin agenttikehyksiin, jotka mahdollistavat:
Jatkuvan oppimisen: Agentit parantavat suorituskykyään vuorovaikutuksessa ympäristön ja käyttäjien kanssa
Tehtäväkohtaisen erikoistumisen: Oppiminen erityisesti organisaation tarpeisiin
Dynaamisen sopeutumisen: Kyky mukautua muuttuviin olosuhteisiin ja vaatimuksiin
Ihmisen ja koneen yhteistyön: Human-in-the-loop -mekanismit asiantuntijatiedon hyödyntämiseen
Kehysten luokittelu
Agenttikehykset voidaan jakaa kahteen pääkategoriaan niiden ensisijaisen tarkoituksen mukaan:
1. Oppimiskehykset (Learning Frameworks)
Vahvistusoppimiseen (Reinforcement Learning) keskittyneet kehykset
Nämä kehykset keskittyvät agenttien kouluttamiseen ja optimointiin vahvistusoppimisen avulla:
VERL (Volcano Engine Reinforcement Learning): Suuren mittakaavan RLHF-koulutus
OpenRLHF: Käyttäjäystävällinen, skaalautuva RLHF-kehys
Agent Lightning: Universaali RL-koulutuslisäosa mille tahansa agenttikehykselle
AGILE: RL-pohjainen kehys human-in-the-loop -oppimisella
Lumos: Modulaarinen agenttikoulutuskehys yhtenäisellä dataformaatilla
Näiden kehysten ydintehtävä on mahdollistaa agenttien oppiminen kokemuksesta käyttäen:
Policy gradient -menetelmiä (PPO, GRPO)
Verifiable rewards -palautetta
Multi-turn interaction -oppimista
Credit assignment -mekanismeja pitkissä sekvensseissä
2. Orkestrointikehykset (Orchestration Frameworks)
Moniagenttijärjestelmien hallintaan ja koordinointiin keskittyneet kehykset
Nämä kehykset tarjoavat infrastruktuurin ja työkalut monimutkaisille agenttityönkuluille:
AutoGen: Event-driven moniagenttikehys
LangGraph: Graafipohjanen tilapidollinen orkestrointi
CrewAI: Roolipohjainen moniagenttikollaboraatio
AutoGPT: Autonomisten agenttien low-code-alusta
AgentScope: Developer-centric moniagenttialusta vikasietoisuudella
Näiden kehysten ydintehtävä on koordinoida agenttien toimintaa tarjoten:
Viestinvälitysmekanismit
Tilanhallinnan (state management)
Työnkulkujen visualisoinnin
Multi-agent collaboration patterns
3. Hybridiratkaisut
Jotkut kehykset yhdistävät molempia lähestymistapoja:
Agent Lightning toimii siltana: se voi lisätä oppimiskyvyn mihin tahansa orkestrointikehykseen
AGILE yhdistää RL-koulutuksen ja human-in-the-loop -orkestroinnin
Vahvistusoppimisen merkitys agenttikehityksessä
Vahvistusoppiminen (RL) on osoittautunut kriittiseksi tekijäksi kehitettäessä adaptiivia, älykkäitä agentteja:
Keskeiset edut:
Outcome-based learning: Oppiminen lopputuloksen perusteella ilman yksityiskohtaisia step-by-step -annotaatioita
Trial-and-error -oppiminen: Luonnollinen tapa oppia monimutkaisia ongelmanratkaisutaitoja
Long-horizon optimization: Kyky optimoida pitkän aikavälin tavoitteita
Deployment context grounding: Oppiminen todellisessa käyttöympäristössä
RL:n haasteet agenteissa:
Pitkät trajektorit (satoihin vuoroihin)
Harva palautesignaali (sparse rewards)
Monimutkainen credit assignment
Multi-agent coordination
Tool use ja external API interactions
Modernit RL-kehykset, kuten VERL ja Agent Lightning, ratkaisevat näitä haasteita erikoistuneilla algoritmeilla ja arkkitehtuureilla.
Dokumentin rakenne
Tämä dokumentti esittelee yksityiskohtaisesti:
Oppimiskehykset: RL-pohjaiset järjestelmät agenttien koulutukseen
Orkestrointikehykset: Moniagenttijärjestelmien hallinta
Hallintapalvelut: Cloud-infrastruktuuri kehysten käyttöönottoon
Käytännön sovellukset: Käyttötapaukset eri kategorioissa


